搜索系统8:搭建hadoop环境
如果只是搜索,那么用solr或者es就可以了。在这个时代,商品太多,用户都不知道什么是合适的,也不知道该搜什么才能搜到用户想要产品。另外app也希望能主动理解用户的需求,给用户推荐合适的商品,现在的淘宝做得就很好。一进首页,就出现了很多我感兴趣但又没买过的商品。这就是推荐系统干的事。要搭建推荐系统,可以使用mahout,使用mahout聚类等会使用到hadoop,本文就是我学习搭建hadoop的笔记。
一、搭建环境与本地模式
现在最新的hadoop是2.8.1,先上官网下载下来,
wget https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz
wget http://image.highersoft.net/jdk-8u261-linux-x64.rpm
解压后,配置环境变量
vi /etc/profile
export HADOOP_HOME=/root/mahout/hadoop-2.8.1
export MAHOUT_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_HOME_WARN_SUPPRESS=not_null
source /etc/profile
这个时候就可以用hadoop本地模式的命令了
hadoop version
应该就能查到版本
hdfs dfs -ls /
同命令hadoop fs -ls /
能查到本机的根目录的文件
二.搭建伪分布式模式
1.进入${HADOOP_HOME}/etc/hadoop,对以下文件进编辑,添加configuration下的内容
<?xml version="1.0"?> <!-- 1.编辑core-site.xml --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost/</value> </property> </configuration> <?xml version="1.0"?> <!-- 2.编辑hdfs-site.xml --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> <?xml version="1.0"?> <!-- 3.编辑mapred-site.xml ,cp mapred-site.xml.template mapred-site.xml--> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> <?xml version="1.0"?> <!-- 4.编辑yarn-site.xml --> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
2.生成公私密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa-t算法为rsa
-P密码为空('')
-f生成密钥文件id_rsa
//执行以下操作,去.ssh文件夹下查看生成的文件
cd ~
ls -al
文件都放在.ssh文件夹
cd .ssh
将生成的id_rsa私钥和公钥id_rsa.pub
追加公钥到~/.ssh/authorized_keys
cat id_rsa.pub >>authorized_keys
非root的情况,新版3.3.1还要增加一步chmod 600 authorized_keys
如果ssh命令执行遇到问题,可用以下查看查看环境是否正确。
查看是否安装sshd(openssh-client,openssh-server)
debian:dpkg -l|grep -i ssh
查看进程是否启动:
ps -ef|grep sshd
我们可创建3种模式(本机、伪分布、分布)的配置,用ln来切换
cp -r hadoop local
cp -r hadoop persudo
cp -r hadoop full
rm -rf hadoop
ln -s persudo hadoop
3.启动hadoop
1.启动前,对hdfs进行格式化:
hadoop namenode -format
伪分布式模式下启动所有进程:
cd ${HADOOP_HOME}/sbin
./start-all.sh
hadoop2.10会出现错误
localhost: Error: JAVA_HOME is not set and could not be found.虽然已经设置了JAVA_HOME,但还需要在${HADOOP_HOME}/etc/hadoop/hadoop-env.sh里添加JAVA_HOME,就能解决问题
如何修改hadoop的ssh连接端口:
cd ${HADOOP_HOME}/etc/hadoopvi hadoop-env.sh
最后添加
export HADOOP_SSH_OPTS="-p 端口号"
如果出现JAVA_HOME环境变量,同样在hadoop-env.sh添加
export JAVA_HOME=/usr/local/jdk1.8.0_92
启动成功会显示以下进程:
root@debian:~/mahout/hadoop-2.8.1/sbin# jps
2610 NameNode
1031 ResourceManager
3114 NodeManager
2700 DataNode
2862 SecondaryNameNode
3262 Jps
4.测试hadoop
创建目录:
hdfs dfs -mkdir -p /usr/zz/hadoop
hdfs dfs –put [本地地址] [hadoop目录]
webui查看hadoop文件系统
netstat -ano |grep 50070
注意hadoop3已经把端口从50070改成9870了,上面的步骤没变
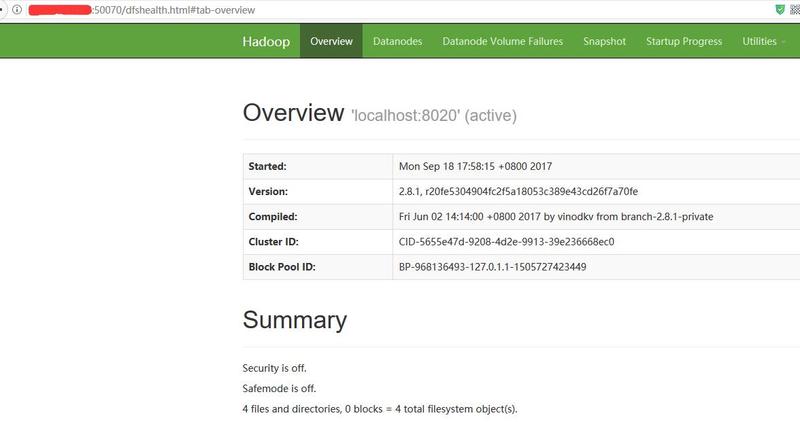
创建hdfs目录,如果出现:
Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x可以在上述的hdfs-site.xml 里添加如下代码来解决:
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>stop-all.sh,如果出现:
localhost: no datanode to stop用以下删除命令即可(root用户):
rm -rf /tmp/hadoop-root/*
如果web页出现不能上传:
Couldn't upload the file查看http请求的host,是否在本地hosts文件里配置
相关阅读
评论:
↓ 广告开始-头部带绿为生活 ↓
↑ 广告结束-尾部支持多点击 ↑